Interfaces
The xaitk-saliency API consists of a number of object-oriented functor interfaces for saliency heatmap generation.
These initial interfaces focus on black-box visual saliency.
We define the two high-level requirements for this initial task: reference image perturbation in preparation for
black-box testing, and saliency heatmap generation utilizing black-box inputs.
We define a few similar interfaces for performing the saliency heatmap generation, separated by the intermediate
algorithmic use cases: image similarity, classification, and object detection.
We explicitly do not require an abstraction for the black-box operations to fit inside.
This is intended to allow for applications using these interfaces while leveraging existing functionality, which only
need to perform data formatting to fit the input defined here.
Note, however, that some interfaces are defined for certain black-box concepts as part of the SMQTK ecosystem (e.g.
in SMQTK-Descriptors,
SMQTK-Classifier,
SMQTK-Relevancy, and other SMQTK-* modules).
These interfaces are based on the plugin and configuration features provided by [SMQTK-Core](https://github.com/Kitware/SMQTK-Core), to allow convenient hooks into implementation, discoverability, and factory generation from runtime configuration. This allows for both opaque discovery of interface implementations from a class-method on the interface class object, as well as instantiation of a concrete instance via a JSON-like configuration fed in from an outside resource.
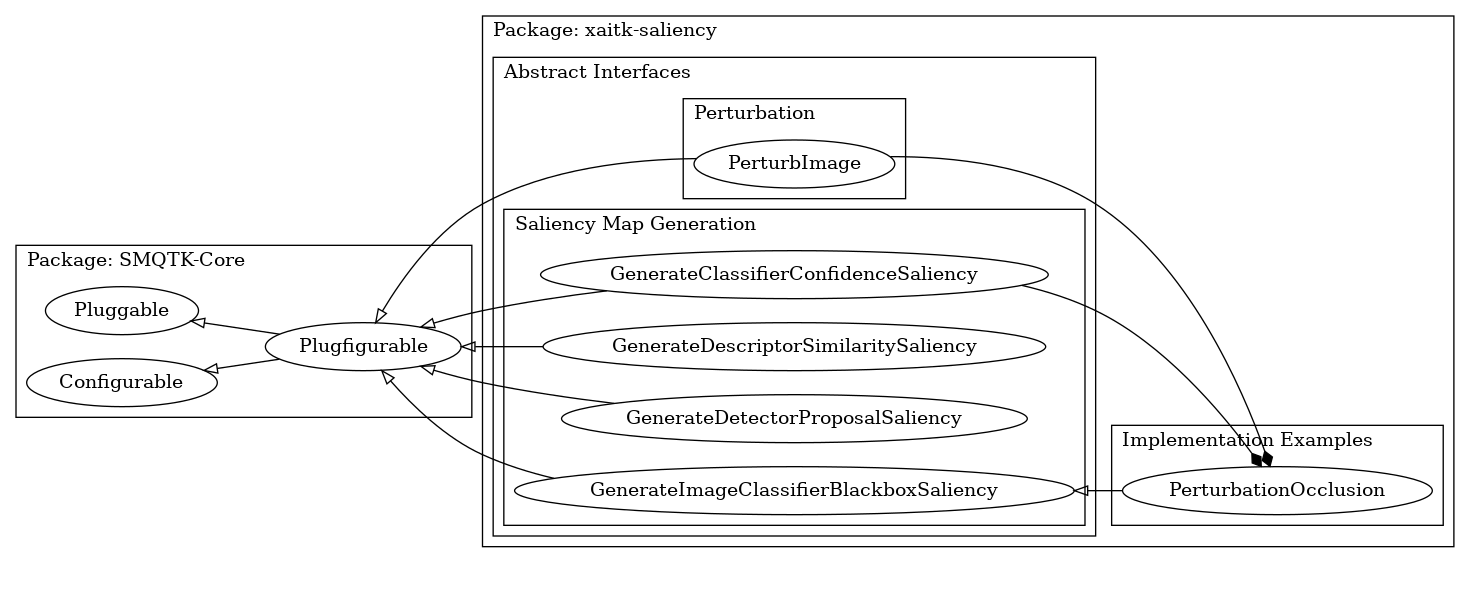
Figure 1: Abstract Interface Inheritance.
Image Perturbation
The PerturbImage interface abstracts the behavior of taking a reference image and generating some number of perturbations of the image along with paired mask matrices that indicate where perturbations have occurred and to what amount.
Implementations should impart no side effects on the input image.
Immediate candidates for implementation of this interface are occlusion-based saliency algorithms [3] that perform perturbations on image pixels.
Interface: PerturbImage
- class xaitk_saliency.interfaces.perturb_image.PerturbImage
Interface abstracting the behavior of taking a reference image and generating some number perturbations in the form of mask matrices indicating where perturbations should occur and to what amount.
Implementations should impart no side effects upon the input image.
- abstract perturb(ref_image: ndarray) ndarray
Transform an input reference image into a number of mask matrices indicating the perturbed regions.
Output mask matrix should be three-dimensional with the format [nMasks x Height x Width], sharing the same height and width to the input reference image. The implementing algorithm may determine the quantity of output masks per input image. These masks should indicate the regions in the corresponding perturbed image that have been modified. Values should be in the [0, 1] range, where a value closer to 1.0 indicates areas of the image that are unperturbed. Note that output mask matrices may be of a floating-point type to allow for fractional perturbation.
- Parameters:
ref_image – Reference image to generate perturbations from.
- Returns:
Mask matrix with shape [nMasks x Height x Width].
Image Occlusion via Perturbation Masks
A common intermediate step in this process is applying the generated perturbation masks to imagery to produce occluded images. We provide two utility functions as baseline implementation to perform this step:
xaitk_saliency.utils.masking.occlude_image_batch- performs the transformation as a batch operationxaitk_saliency.utils.masking.occlude_image_streaming- performs the transformation in a streaming method with optional parallelization in that streaming
While the batch version is simpler and in many cases the faster of the two versions, the streaming version may be more applicable to large image masks or when a great deal of masks are being input, where in such cases the batch version would exceed available memory.
- xaitk_saliency.utils.masking.occlude_image_batch(ref_image: ndarray, masks: ndarray, fill: int | Sequence[int] | ndarray | None = None, threads: int | None = None) ndarray
Apply a number of input occlusion masks to the given reference image, producing a list of images equivalent in length, and parallel in order, to the input masks. This batch version will compute all occluded images and returns them all in one large matrix.
We expect the “mask” matrices and the image to be the same height and width, and for the mask matrix values to be in the [0, 1] range. In the mask matrix, values closer to 1 correspond to regions of the image that should NOT be occluded. E.g. a 0 in the mask will translate to fully occluding the corresponding location in the source image.
We optionally take in a “fill” that alpha-blend into masked regions of the input ref_image. fill may be either a scalar, sequence of scalars, or another image matrix congruent in shape to the ref_image. When fill is a scalar or a sequence of scalars, the scalars should be in the same data-type and value range as the input image. A sequence of scalars should be the same length as there are channels in the ref_image. When fill is an image matrix it should follow the format of [H x W] or [H x W x C], should be in the same dtype and value range as ref_image and should match the same number of channels if channels are provided. When no fill is passed, black is used (default absence of color).
Images output will mirror the input image format. As such, the fill value passed must be compatible with the input image channels for broadcasting. For example, a single channel input will not be able to be broadcast against a multi-channel fill input. A ValueError will be raised by the underlying numpy call in such cases.
NOTE: Due to the batch nature of this function, utilizing a fill color will consistently utilize more RAM due to the use of alpha blending
- Assumptions:
Mask input is per-pixel. Does not accept per-channel masks.
Fill value input is in an applicable value range supported by the input image format, which is mirrored in output images.
- Parameters:
ref_image – Reference image to generate perturbations from.
masks – Mask matrix input of shape [N x H x W] where height and width dimensions are the same size as the input ref_image.
fill – Optional fill for alpha-blending based on the input masks for the occluded regions as a scalar value, a per-channel sequence or a shape-matched image.
threads – Optional number of threads to use for parallelism when set to a positive integer. If 0, a negative value, or None, work will be performed on the main-thread in-line.
- Raises:
ValueError – The input mask matrix was not three-dimensional, its last two dimensions did not match the shape of the input imagery, or the input fill value could not be broadcast against the input image.
- Returns:
A numpy array of masked images.
- xaitk_saliency.utils.masking.occlude_image_streaming(ref_image: ndarray, masks: Iterable[ndarray], fill: int | Sequence[int] | ndarray | None = None, threads: int | None = None) Generator[ndarray, None, None]
Apply a number of input occlusion masks to the given reference image, producing a list of images equivalent in length, and parallel in order, to the input masks. This streaming version will return an iterator that yields occluded image matrices.
We expect the “mask” matrices and the image to be the same height and width, and for the mask matrix values to be in the [0, 1] range. In the mask matrix, values closer to 1 correspond to regions of the image that should NOT be occluded. E.g. a 0 in the mask will translate to fully occluding the corresponding location in the source image.
We optionally take in a “fill” that alpha-blend into masked regions of the input ref_image. fill may be either a scalar, sequence of scalars, or another image matrix congruent in shape to the ref_image. When fill is a scalar or a sequence of scalars, the scalars should be in the same data-type and value range as the input image. A sequence of scalars should be the same length as there are channels in the ref_image. When fill is an image matrix it should follow the format of [H x W] or [H x W x C], should be in the same dtype and value range as ref_image and should match the same number of channels if channels are provided. When no fill is passed, black is used (default absence of color).
Images output will mirror the input image format. As such, the fill value passed must be compatible with the input image channels for broadcasting. For example, a single channel input will not be able to be broadcast against a multi-channel fill input. A ValueError will be raised by the underlying numpy call in such cases.
- Assumptions:
Mask input is per-pixel. Does not accept per-channel masks.
Fill value input is in an applicable value range supported by the input image format, which is mirrored in output images.
- Parameters:
ref_image – Original base image
masks – Mask images in the [N, Height, Weight] shape format.
fill – Optional fill for alpha-blending based on the input masks for the occluded regions as a scalar value, a per-channel sequence or a shape-matched image.
threads – Optional number of threads to use for parallelism when set to a positive integer. If 0, a negative value, or None, work will be performed on the main-thread in-line.
- Raises:
ValueError – One or more input masks in the input iterable did not match shape of the input reference image.
- Returns:
A generator of numpy array masked images.
Heatmap Generation
These interfaces comprise a family of siblings that all perform a similar transformation, but require different standard inputs. There is no standard to rule them all without being so abstract that it would break the concept of interface abstraction, or the ability to substitute any arbitrary implementations of the interface without interrupting successful execution. Each interface is intended to handle different black-box outputs from different algorithmic categories. In the future, as additional algorithmic categories are identified for which saliency map generation is applicable, additional interfaces may be defined and added to this initial repertoire.
Interface: GenerateClassifierConfidenceSaliency
This interface proposes that implementations transform black-box image classification scores into saliency heatmaps.
This should require a sequence of per-class confidences predicted on the reference image, a number of per-class
confidences as predicted on perturbed images, as well as the masks of the reference image perturbations (as would be
output from a PerturbImage implementation).
Implementations should use this input to generate a visual saliency heatmap for each input “class” in the input. This is both an effort to vectorize the operation for optimal performance, as well as to allow some algorithms to take advantage of differences in classification behavior for other classes to influence heatmap generation. For classifiers that generate many class label predictions, it is intended that only a subset of relevant class predictions need be provided here if computational performance is a consideration.
An immediate candidate implementation for this interface is the RISE algorithm [2] and occlusion-based saliency algorithms [3] that generate saliency heatmaps.
- class xaitk_saliency.interfaces.gen_classifier_conf_sal.GenerateClassifierConfidenceSaliency
Visual saliency map generation interface whose implementations transform black-box image classification scores into saliency heatmaps.
This should require a sequence of per-class confidences predicted on the reference image, a number of per-class confidences as predicted on perturbed images, as well as the masks of the reference image perturbations (as would be output from a
xaitk_saliency.interfaces.perturb_image.PerturbImageimplementation).Implementations should use this input to generate a visual saliency heatmap for each input “class” in the input. This is both an effort to vectorize the operation for optimal performance, as well as to allow some algorithms to take advantage of differences in classification behavior for other classes to influence heatmap generation. For classifiers that generate many class label predictions, it is intended that only a subset of relevant class predictions need be provided here if computational performance is a consideration.
- abstract generate(reference: ndarray, perturbed: ndarray, perturbed_masks: ndarray) ndarray
Generate a visual saliency heatmap matrix given the black-box classifier output on a reference image, the same classifier output on perturbed images and the masks of the visual perturbations.
Perturbation mask input into the perturbed_masks parameter here is equivalent to the perturbation mask output from a
xaitk_saliency.interfaces.perturb_image.PerturbImage.perturb()method implementation. These should have the shape [nMasks x H x W], and values in range [0, 1], where a value closer to 1 indicate areas of the image that are unperturbed. Note the type of values in masks can be either integer, floating point or boolean within the above range definition. Implementations are responsible for handling these expected variations.Generated saliency heatmap matrices should be floating-point typed and be composed of values in the [-1,1] range. Positive values of the saliency heatmaps indicate regions which increase class confidence scores, while negative values indicate regions which decrease class confidence scores according to the model that generated input confidence values.
- Parameters:
reference – Reference image predicted class-confidence vector, as a numpy.ndarray, for all classes that require saliency map generation. This should have a shape [nClasses], be float-typed and with values in the [0,1] range.
perturbed_conf – Perturbed image predicted class confidence matrix. Classes represented in this matrix should be congruent to classes represented in the reference vector. This should have a shape [nMasks x nClasses], be float-typed and with values in the [0,1] range.
perturbed_masks – Perturbation masks numpy.ndarray over the reference image. This should be parallel in association to the classification results input into the perturbed_conf parameter. This should have a shape [nMasks x H x W], and values in range [0, 1], where a value closer to 1 indicate areas of the image that are unperturbed.
- Returns:
Generated visual saliency heatmap for each input class as a float-type numpy.ndarray of shape [nClasses x H x W].
Interface: GenerateDescriptorSimilaritySaliency
This interface proposes that implementations require externally generated feature-vectors for two reference images
between which we are trying to discern the feature-space saliency.
This also requires the feature-vectors for perturbed images as well as the masks of the perturbations as would be
output from a PerturbImage implementation.
We expect perturbations to be relative to the second reference image feature-vector.
An immediate candidate implementation for this interface is the Similarity Based Saliency Maps (SBSM) algorithm [1].
- class xaitk_saliency.interfaces.gen_descriptor_sim_sal.GenerateDescriptorSimilaritySaliency
Visual saliency map generation interface whose implementations transform black-box feature vectors from multiple references and perturbations into saliency heatmaps.
This transformation requires a reference image, and a number of query images all translated into feature vectors via some black-box means. We are trying to discern the feature-space saliency between the reference image and each query image. This also requires the feature vectors for perturbed versions of the reference images as well as the masks of the perturbations as would be output from a
xaitk_saliency.interfaces.perturb_image.PerturbImageimplementation. The resulting saliency heatmaps are relative to the reference image.- abstract generate(ref_descr: ndarray, query_descrs: ndarray, perturbed_descrs: ndarray, perturbed_masks: ndarray) ndarray
Generate a matrix of visual saliency heatmaps given the black-box descriptor generation output on a reference image, several query images, perturbed versions of the reference image and the masks of the visual perturbations.
Perturbation mask input into the perturbed_masks parameter here is equivalent to the perturbation mask output from a
xaitk_saliency.interfaces.perturb_image.PerturbImage.perturb()method implementation. We expect perturbations to be relative to the reference image. These should have the shape [nMasks x H x W], and values in range [0, 1], where a value closer to 1 indicates areas of the image that are unperturbed. Note the type of values in masks can be either integer, floating point or boolean within the above range definition. Implementations are responsible for handling these expected variations.Generated saliency heatmap matrices should be floating-point typed and be composed of values in the [-1,1] range. Positive values of the saliency heatmaps indicate regions which increase image similarity scores, while negative values indicate regions which decrease image similarity scores according to the model that generated input feature vectors.
- Parameters:
ref_descr – Reference image float feature vector, shape [nFeats]
query_descrs – Query image float feature vectors, shape [nQueryImgs x nFeats].
perturbed_descrs – Feature vectors of reference image perturbations, float typed of shape [nMasks x nFeats].
perturbed_masks – Perturbation masks numpy.ndarray over the query image. This should be parallel in association to the perturbed_descrs parameter. This should have a shape [nMasks x H x W], and values in range [0, 1], where a value closer to 1 indicates areas of the image that are unperturbed.
- Returns:
Generated saliency heatmaps as a float-typed numpy.ndarray with shape [nQueryImgs x H x W].
Interface: GenerateDetectorProposalSaliency
This interface proposes that implementations transform black-box image object detection predictions into visual
saliency heatmaps.
This should require externally generated object detection predictions over some image, along with predictions for
perturbed images and the perturbation masks for those images as would be output from a PerturbImage implementation.
Object detection representations used here would need to encapsulate localization information (i.e. bounding box
regions), class scores, and objectness scores (if applicable to the detector, such as YOLOv3).
Object detections are converted into (4+1+nClasses) vectors (4 indices for bounding box locations, 1 index for
objectness, and nClasses indices for different object classes).
Implementations should use this input to generate a visual saliency heatmap for each input detection.
We assume that an input detection is coupled with a single truth class (or a single leaf node in a hierarchical
structure).
Input detections on the reference image may be drawn from ground truth or predictions as desired by the use case.
As for perturbed image detections, we expect those to usually be decoupled from the source of reference image
detections, which is why below we formulate the shape of perturbed image detects with nProps instead of nDets
(though the value of that axis may be the same in some cases).
A candidate implementation for this interface is the D-RISE [4] algorithm.
- class xaitk_saliency.interfaces.gen_detector_prop_sal.GenerateDetectorProposalSaliency
This interface proposes that implementations transform black-box image object detection predictions into visual saliency heatmaps. This should require externally-generated object detection predictions over some image, along with predictions for perturbed images and the perturbation masks for those images as would be output from a
xaitk_saliency.interfaces.perturb_image.PerturbImageimplementation.Object detection representations used here would need to encapsulate localization information (i.e. bounding box regions), class scores, and objectness scores (if applicable to the detector, such as YOLOv3). Object detections are converted into (4+1+nClasses) vectors (4 indices for bounding box locations, 1 index for objectness, and nClasses indices for different object classes).
- abstract generate(ref_dets: ndarray, perturbed_dets: ndarray, perturbed_masks: ndarray) ndarray
Generate visual saliency heatmap matrices for each reference detection, describing what visual information contributed to the associated reference detection.
We expect input detections to come from a black-box source that outputs our minimum requirements of a bounding-box, per-class scores. Objectness scores are required in our input format, but not necessarily from detection black-box methods as there is a sensible default value for this. See the
format_detection()helper function for assistance in forming our input format, which includes this optional default fill-in. We expect objectness is a confidence score valued in the inclusive[0,1]range. We also expect classification scores to be in the inclusive[0,1]range.We assume that an input detection is coupled with a single truth class (or a single leaf node in a hierarchical structure). Detections input as references (
ref_detsparameter) may be either ground truth or predicted detections. As for perturbed image detections input (perturbed_dets), we expect the quantity of detections to be decoupled from the source of reference image detections, which is why below we formulate the shape of perturbed image detections with nProps instead of nDets.Perturbation mask input into the perturbed_masks parameter here is equivalent to the perturbation mask output from a
xaitk_saliency.interfaces.perturb_image.PerturbImage.perturb()method implementation. These should have the shape [nMasks x H x W], and values in range [0, 1], where a value closer to 1 indicate areas of the image that are unperturbed. Note the type of values in masks can be either integer, floating point or boolean within the above range definition. Implementations are responsible for handling these expected variations.Generated saliency heatmap matrices should be floating-point typed and be composed of values in the [-1,1] range. Positive values of the saliency heatmaps indicate regions which increase object detection scores, while negative values indicate regions which decrease object detection scores according to the model that generated input object detections.
- Parameters:
ref_dets – Detections, objectness and class scores on a reference image as a float-typed array with shape [nDets x (4+1+nClasses)].
perturbed_dets – Object detections, objectness and class scores for perturbed variations of the reference image. We expect this to be a float-types array with shape [nMasks x nProps x (4+1+nClasses)].
perturb_masks – Perturbation masks numpy.ndarray over the reference image. This should be parallel in association to the detection propositions input into the perturbed_dets parameter. This should have a shape [nMasks x H x W], and values in range [0, 1], where a value closer to 1 indicate areas of the image that are unperturbed.
- Returns:
A visual saliency heatmap matrix describing each input reference detection. These will be float-typed arrays with shape [nDets x H x W].
Detection formatting helper
The GenerateDetectorProposalSaliency.generate() method takes in a
specifically formatted matrix that combines three aspects of common
detector model outputs:
* bounding boxes
* objectness scores
* classification scores
We provide a helper function to merge distinct output data into the unified format.
- xaitk_saliency.utils.detection.format_detection(bbox_mat: ndarray, classification_mat: ndarray, objectness: ndarray | None = None) ndarray
Combine detection and classification output, with optional objectness output, into the combined format required for
GenerateDetectorProposalSaliency.generate()*_detsinput parameters.We enforce some shape consistency so that we can create a valid output matrix. The input bounding box matrix should be of shape
[nDets x 4], the classification matrix should be of shape[nDets x nClasses], and the objectness vector, if provided, should be of sizenDets.If an
objectnessscore vector is not provided, we assume a vector of 1’s.The output of this function is a matrix that is of shape
[nDets x (4+1+nClasses)]. This is the result of horizontally stacking the input in bbox, objectness and classification order. The output matrix data-type will follow numpy’s rules about safe-casting given the combination of input matrix types.In exceptions about shape mismatches, index 0 refers to the
bbox_matinput, index 1 refers to theobjectnessvector, and index 2 refers to theclassification_mat.- Parameters:
bbox_mat – Matrix of bounding boxes. This matrix should have the shape
[nDets x 4]. The format of each row-vector is not important but generally expected to be[left, top, right, bottom]pixel coordinates. This matrix must be of a type that is float-castable.classification_mat – Matrix of classification scores from the detector or detection classifier. This should have the shape of
[nDets x nClasses]. This matrix must be of a type that is float-castable.objectness – Optional vector of objectness scores for input detections. This is optional as not all detection models output this aspect. When provided, this should be a vector of ints/floats of size
nDetsto match the other parameter shapes.
- Raises:
ValueError – When input matrix shapes are mismatched such that they cannot be horizontally stacked.
- Returns:
Matrix combining bounding box, objectness and class confidences.
End-to-End Saliency Generation
Unlike the previous saliency heatmap generation interfaces, this interface uses a black-box classifier as input along with a reference image to generate visual saliency heatmaps.
A candidate implementation for this interface is the PerturbationOcclusion implementation or one of its
sub-implementations (RISEStack or SlidingWindowStack).
Interface: GenerateImageClassifierBlackboxSaliency
- class xaitk_saliency.interfaces.gen_image_classifier_blackbox_sal.GenerateImageClassifierBlackboxSaliency
This interface for algorithms takes a reference image and an image classifier black-box algorithm, then generates a number of visual saliency heatmap matrices, one for each class output by the classifier black box.
A classifier black box needs to be input, which requires some specification in how to operate the black box. The smqtk_classifier.ClassifyImage abstract interface is used to provide a minimal form that a black-box classifier requires: be able to classify an image into confidences for some number of class labels.
Generates a visual saliency heatmap for each input class as a float-type numpy.ndarray of shape [nClasses x H x W].
- generate(ref_image: ndarray, blackbox: ClassifyImage) ndarray
Generates per-class visual saliency heatmaps for some classifier black box over some image of interest.
The input reference image is expected to be in matrix form and be in either a H x W or H x W x C shape format.
Output saliency map matrix should be (1) in the shape nClasses x H x W, (2) floating-point typed, and (3) composed of values in the [-1, 1] range. nClasses should be the quantity of unique class labels output by the given classifier black box. While specific algorithms determine the quantity of heatmaps returned, the height and width of returned heatmaps should be consistent with the input image, i.e. the H and W dimensions should match in size to the reference image’s H and W dimensions. Positive values of the saliency heatmaps indicate regions that increase respective class confidence scores, while negative values indicate regions that decrease respective class confidence scores according to the given black-box classifier.
- Parameters:
ref_image – Reference image over which visual saliency heatmaps will be generated.
blackbox – The black-box classifier handle to perform arbitrary operations on in order to deduce visual saliency.
- Raises:
ShapeMismatchError – The implementation result visual saliency heatmap matrix did not have matching height and width components to the reference image.
- Returns:
A number of visual saliency heatmaps equivalent in number to the quantity of class labels output by the black-box classifier.
Interface: GenerateImageSimilarityBlackboxSaliency
- class xaitk_saliency.interfaces.gen_image_similarity_blackbox_sal.GenerateImageSimilarityBlackboxSaliency
This interface describes the generation of visual saliency heatmaps based on the similarity of a reference image to a number of query images. Similarity is deduced from the output of a black-box image feature vector generator that transforms each image to an embedding space.
The resulting saliency maps are relative to the reference image. As such, each map denotes regions in the reference image that make it more or less similar to the corresponding query image.
The smqtk_descriptors.ImageDescriptorGenerator interface is used to provide a common format for image feature vector generation.
- generate(ref_image: ndarray, query_images: Sequence[ndarray], blackbox: ImageDescriptorGenerator) ndarray
Generates visual saliency maps based on the similarity of the reference image to each query image determined by the output of the blackbox feature vector generator.
The input reference image is expected to be a matrix in either a H x W or H x W x C shape format. The input query images should be a sequence of matrices, each of which should also be in either H x W or H x W x C format. Each query image is not required to have the same shape, however.
The output saliency map matrix should be (1) of shape nQueryImgs x H x W with matching height and width to the reference image, (2) floating-point typed, and (3) composed of values in the [-1, 1] range.
The (0, 1] range is intended to describe regions that are positively salient, and the [-1, 0) range is intended to describe regions that are negatively salient. Positive values of each saliency heatmap indicate regions of the reference image that increase its similarity to the corresponding query image, while negative values indicate regions that actively decrease its similarity to the corresponding query image.
Similarity is determined by the output of the feature vector generator and implementation specifics.
- Parameters:
ref_image – Reference image to compute saliency for.
query_images – Query images to compare the reference image to.
blackbox – Black-box image feature vector generator.
- Raises:
ShapeMismatchError – The implementation’s resulting heatmap matrix did not have matching height and width components to the reference image.
- Returns:
A matrix of saliency heatmaps relative to the reference image with shape nQueryImgs x H x W.
Interface: GenerateObjectDetectorBlackboxSaliency
- class xaitk_saliency.interfaces.gen_object_detector_blackbox_sal.GenerateObjectDetectorBlackboxSaliency
This interface describes the generation of visual saliency heatmaps for input object detections with respect to a given black box object detection and classification model.
This transformation requires reference detections to focus on explaining, and the image those detections were drawn from. For compatibility, the input detections specification are split into three separate inputs: bounding boxes, scores, and objectness. A visual saliency heatmap is generated for each input detection.
The smqtk_detection.DetectImageObjects abstract interface is used to provide a common format for a black-box object detector.
- generate(ref_image: ndarray, bboxes: ndarray, scores: ndarray, blackbox: DetectImageObjects, objectness: ndarray | None = None) ndarray
Generate per-detection visual saliency heatmaps for some object detector black-box over some input reference detections from some input reference image.
The input reference image is expected to be a matrix in either [H x W] or [H x W x C] shape format.
The reference detections are represented by three separate inputs: bounding boxes, scores, and objectness. The input bounding boxes are expected to be a matrix with shape [nDets x 4] where each row is the bounding box of a single detection in xyxy format. The input scores are expected to be a matrix with shape [nDets x nClasses] where each row is the scores for each class for a single detection. The order of each class score should match the order returned by the input black-box algorithm. The optional input objectness is expected to be a vector of length nDets containing the objectness score (single float value) for each reference detection. If this is not provided, it is assumed that each detection has an objectness score of 1.
If your detections consist of a single class prediction and confidence score instead of scores for each class, it is best practice to replace the objectness score with the confidence score and use a one-hot encoding of the prediction as the class scores.
The output saliency map matrix should be (1) in the shape [nDets x H x W] where H and W are the height and width respectively of the input reference image, (2) floating-point typed, and (3) composed of values in the [-1, 1] range.
The (0, 1] range is intended to describe regions that are positively salient, and the [-1, 0) range is intended to describe regions that are negatively salient. Positive values of the saliency heatmaps indicate regions that increase detection locality and class confidence scores, while negative values indicate regions that actively decrease detection locality and class confidence scores.
- Parameters:
ref_image – Reference image that the input reference detections belong to.
bboxes – The bounding boxes in xyxy format of the reference detections to generate visual saliency maps for. This should be a matrix with shape [nDets x 4].
scores – The class scores of the reference detections to generate visual saliency maps for. This should be a matrix with shape [nDets x nClasses]. The order of the scores should match that returned by the input black-box detection algorithm.
blackbox – The black-box object detector to perform arbitrary operations on in order to deduce visual saliency.
objectness – Optional objectness score for each reference detection. This should be a vector of length nDets. If not provided, it is assumed that each detection has an objectness score of 1.
- Raises:
ValueError – The input reference image had an unexpected number of dimensions.
ValueError – The input bounding boxes had a width other than 4.
ValueError – The input bounding boxes, scores, and/or objectness scores do not match in quantity.
ShapeMismatchError – The implementation result visual saliency heatmap matrix did not have matching height and width components to the reference image.
ShapeMismatchError – The quantity of resulting heatmaps did not match the quantity of input reference detections.
- Returns:
A number of visual saliency heatmaps, one for each input reference detection. This is a single matrix of shape [nDets x H x W] where H and W are the height and width respectively of the input reference image.
Saliency Metrics
Interface: SaliencyMetric
- class xaitk_saliency.interfaces.saliency_metric.SaliencyMetric
This interface outlines the computation of a given metric when provided with a single input saliency map.
- abstract compute(sal_map: ndarray) float
Given up to two saliency maps, and additional parameters, return some given metric about the saliency map(s).
- Parameters:
sal_map – An input saliency map.
- Returns:
Returns a single scalar value representing an implementation’s computed metric. Implementations should impart no side effects upon the input saliency map.
- property name: str
Returns the name of the SaliencyMetric instance.
This property provides a convenient way to retrieve the name of the class instance, which can be useful for logging, debugging, or display purposes.
- Returns:
str: The name of the SaliencyMetric instance.
Code Examples
For Jupyter Notebook examples of xaitk-saliency interfaces, see the examples/ directory of the project.
References
1. Dong B, Collins R, Hoogs A. Explainability for Content-Based Image Retrieval. InCVPR Workshops 2019 Jun (pp. 95-98). 2. Petsiuk V, Das A, Saenko K. Rise: Randomized input sampling for explanation of black-box models. arXiv preprint arXiv:1806.07421. 2018 Jun 19. 3. Zeiler MD, Fergus R. Visualizing and understanding convolutional networks (2013). arXiv preprint arXiv:1311.2901. 2013. 4. Petsiuk V, Jain R, Manjunatha V, Morariu VI, Mehra A, Ordonez V, Saenko K. Black-box explanation of object detectors via saliency maps. arXiv preprint arXiv:2006.03204. 2020 Jun 5.