Saliency Generation with Deep Reinforcement Learning
Introduction
This notebook shows usage of the xaitk-saliency API to gain insight into the behavior of a trained deep reinforcement learning agent in an Atari 2600 environment.
This example is based on this paper and the corresponding code in this Github repository. The authors use the Asynchronous Advantage Actor Critic (A3C) algorithm with a LSTM-CNN policy network to train several agents for automated gameplay in different Atari 2600 games. They also implement a method for generating saliency maps using image perturbation. Here, we will try to reproduce their results using the xaitk-saliency API, focusing on the Breakout-v0 environment.
Table of Contents
References
Greydanus, Samuel, et al. “Visualizing and Understanding Atari Agents.” International Conference on Machine Learning. PMLR, 2018.
To run this notebook in Colab, use the link below:
![]()
Set Up Environment
Note for Colab users: after setting up the environment, you may need to “Restart Runtime” in order to resolve package version conflicts (see the README for more info).
import sys # noqa
!{sys.executable} -m pip install -qU pip
!{sys.executable} -m pip install -q xaitk-saliency
!{sys.executable} -m pip install -q "torch>=1.9.0"
!{sys.executable} -m pip install -q "torchvision>=0.10.0"
!{sys.executable} -m pip install -q "gym[atari,accept-rom-license]==0.26.2"
# Install the libGL-less version of OpenCV.
!{sys.executable} -m pip uninstall -qy "opencv-python" "opencv-python-headless" # make sure they're both gone.
!{sys.executable} -m pip install -q "opencv-python-headless"
# Force reinstallation to resolve incompatibilities between dependencies
!{sys.executable} -m pip install -q --force-reinstall --no-cache-dir \
"numpy<2.0" "packaging<24.0" \
opencv-python-headless scikit-image
Create Atari Environment
Here we create the Breakout environment for our agent using Gym.
Our agent has 4 different actions to choose from:
1. Do nothing
2. Fire
3. Move right
4. Move left
import gym
env_name = "ALE/Breakout-v5"
env = gym.make(env_name)
# Set seed for reproducibility
env.seed(1)
action_space = env.unwrapped.get_action_meanings()
print(f"Action space: {action_space}")
Action space: ['NOOP', 'FIRE', 'RIGHT', 'LEFT']
Define Policy Network
This policy network implementation is taken directly from the author’s original implementation. It consists of four convolutional layers, an LSTM layer, and two separate fully-connected layers for the value and policy function predictions.
import glob
from typing import Any
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as functional
class NNPolicy(torch.nn.Module):
"""an actor-critic neural network."""
def __init__(self, channels: int, num_actions: int) -> None:
"""Initialize model."""
super().__init__()
self.conv1 = nn.Conv2d(channels, 32, 3, stride=2, padding=1)
self.conv2 = nn.Conv2d(32, 32, 3, stride=2, padding=1)
self.conv3 = nn.Conv2d(32, 32, 3, stride=2, padding=1)
self.conv4 = nn.Conv2d(32, 32, 3, stride=2, padding=1)
self.lstm = nn.LSTMCell(32 * 5 * 5, 256)
self.critic_linear, self.actor_linear = nn.Linear(256, 1), nn.Linear(256, num_actions)
def forward(
self,
inputs: tuple[torch.Tensor, tuple[torch.Tensor, torch.Tensor]],
) -> tuple[torch.Tensor, torch.Tensor, tuple[torch.Tensor, torch.Tensor]]:
"""Move game forward ones step."""
inputs, (hx, cx) = inputs
x = functional.elu(self.conv1(inputs))
x = functional.elu(self.conv2(x))
x = functional.elu(self.conv3(x))
x = functional.elu(self.conv4(x))
x = x.view(-1, 32 * 5 * 5)
hx, cx = self.lstm(x, (hx, cx))
return self.critic_linear(hx), self.actor_linear(hx), (hx, cx)
def try_load(self, save_dir: str, checkpoint: str = "*.tar") -> int:
"""."""
paths = glob.glob(save_dir + checkpoint)
step = 0
if len(paths) > 0:
ckpts = [int(s.split(".")[-2]) for s in paths]
ix = np.argmax(ckpts)
step = ckpts[ix]
self.load_state_dict(torch.load(paths[ix]))
print("\tno saved models") if step == 0 else print(f"\tloaded model: {paths[ix]}")
return step
Download Pretrained Model
The authors provide pretrained agents here for the different environments they used (both the “strong” and “overfit” variants, see the original paper for details). We will use the “strong” Breakout agent for our purposes.
We provide the Breakout model checkpoint here for easy download, although we refer the reader to the link above which contains a zip file of all the pretrained agents, including both “strong” and “overfit” agents.
import os
import urllib.request
root_dir = "data/pretrained_agents/breakout-v0/"
os.makedirs(root_dir, exist_ok=True)
model_checkpoint = os.path.join(root_dir, "strong.40.tar")
_ = urllib.request.urlretrieve(
"https://data.kitware.com/api/v1/item/62325a1d4acac99f426f21e9/download",
model_checkpoint,
)
Load Pretrained Model
Here we load the downloaded model into an instance of the policy function class.
model = NNPolicy(channels=1, num_actions=env.action_space.n)
model.try_load(root_dir, checkpoint="*.tar")
# Seed seed for reproducibility
_ = torch.manual_seed(1)
loaded model: data/pretrained_agents/breakout-v0/strong.40.tar
Define Rollout Function
This function carries out the pretrained agent’s policy for a defined number of frames in our Breakout environment. At each step, the current game frame is run through our policy model to get the predicted best action and the agent takes that action. The state of the game is stored after after each step.
import cv2
def prepro(img: np.ndarray) -> np.ndarray:
"""Standard frame pre-processing based on Greydanus et al., '18'."""
return cv2.resize(src=img[35:195].mean(2), dsize=(80, 80)).astype(np.float32) / 255.0
def rollout(model: torch.nn.Module, env: gym.core.Env, max_ep_len: int) -> dict[str, Any]:
"""Plays the game and return the game history."""
history = {"ins": [], "logits": [], "values": [], "outs": [], "hx": [], "cx": []}
state = torch.Tensor(prepro(env.reset()[0])) # get first state
episode_length, epr, _eploss, done = 0, 0, 0, False # bookkeeping
hx, cx = torch.zeros(1, 256), torch.zeros(1, 256)
# iterate through each frame in episode
while not done and episode_length <= max_ep_len:
episode_length += 1
# get game state
model_inp = (state.view(1, 1, 80, 80), (hx, cx))
# run through model
value, logit, (hx, cx) = model(model_inp)
hx, cx = hx.data, cx.data
# action probabilities
prob = functional.softmax(logit)
# best action
action = prob.max(1)[1].data
# take best action
obs, reward, done, _expert_policy, _ = env.step(action.numpy()[0])
# update reward
state = torch.Tensor(prepro(obs))
epr += reward
# save state
history["ins"].append(obs) # game state after taking action
history["hx"].append(hx.squeeze(0).data.numpy()) # LSTM hx output
history["cx"].append(cx.squeeze(0).data.numpy()) # LSTM cx output
history["logits"].append(logit.data.numpy()[0]) # actor output
history["values"].append(value.data.numpy()[0]) # critic output
history["outs"].append(prob.data.numpy()[0]) # action probabilities
print(f"\tstep # {episode_length}, reward {epr:.0f}", end="\r")
return history
Play Breakout
Our pretrained agent will now play the game for up to 3,000 frames. We will create a short video clip from a slice of the game state so we can see the agent in action. The agent shows a “tunneling” behavior, which was also noted by the original authors in the paper referenced above.
import warnings
import matplotlib.pyplot as plt
warnings.filterwarnings("ignore")
# Play game
print("Rolling out policy...")
history = rollout(model, env, max_ep_len=int(3e3))
# Create video from frames
print("\nCreating video...")
fps = 30
w = history["ins"][0].shape[1]
h = history["ins"][0].shape[0]
out = cv2.VideoWriter("data/breakout.mp4", cv2.VideoWriter_fourcc(*"vp09"), fps, (w, h))
start_frame = 638
end_frame = 1238
for i in range(start_frame, end_frame + 1):
frame = cv2.cvtColor(history["ins"][i], cv2.COLOR_RGB2BGR) # Convert to BRG for cv2 standards
out.write(frame)
out.release()
print("Done")
Rolling out policy...
step # 2179, reward 258
Creating video...
Done
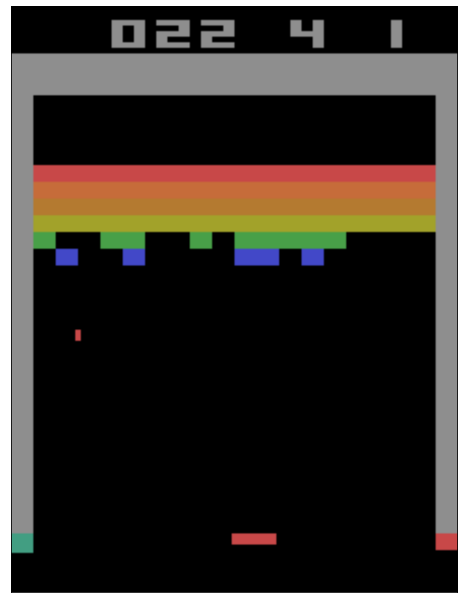
Here we show a single frame from the game.
f = plt.figure(figsize=[8, 12])
frame_ix = 1070
plt.imshow(history["ins"][frame_ix])
for a in f.axes:
a.get_xaxis().set_visible(False)
a.get_yaxis().set_visible(False)
plt.show()
Here we show a recorded video from the game. This video is saved as breakout.mp4 in the current directory.
Note that this file will not exist, and the video will not be visible, until the notebook is run.
%%HTML
<div align="middle">
<video width="50%" controls>
<source src="data/breakout.mp4" type="video/mp4">
</video></div>
Defining the Application
Our saliency application has four parameters:
start_frame - the first frame to perform saliency generation for
end_frame - the last frame to perform saliency generation for
perturber - the PerturbImage implementation to use
saliency_gen - the GenerateClassifierConficdenceSaliency implementation to use
The application will create saliency maps for both the actor (policy function) and the critic (value function) for each frame from start_frame to end_frame using the image perturber and saliency generator that you pass it. Salient parts of each frame will be highlighted in blue for the actor and in red for the critic and a video will be created from this set of highlighted game frames. This gives a single representation for each frame of where both models are looking to make their predictions.
To speed up this process, the application utilizes multiple processing threads, one for each frame. This will use a good amount of system memory so be cautious.
import concurrent.futures
import multiprocessing
import threading
from scipy.ndimage.filters import gaussian_filter
from xaitk_saliency import GenerateClassifierConfidenceSaliency, PerturbImage
from xaitk_saliency.utils.masking import occlude_image_batch
actor_sal_maps = []
critic_sal_maps = []
print_lock = threading.Lock() # Lock to control thread printing
def print_helper(to_print: str, verbose: int) -> None:
"""."""
if verbose:
with print_lock:
print(to_print)
def gen_sal_maps(
img_idx: int,
sal_idx: int,
perturber: PerturbImage,
saliency_gen: GenerateClassifierConfidenceSaliency,
verbose: int = 0,
) -> None:
"""Generates actor and critic saliency maps on a per-frame basis given an image
perturber and a saliency map generation implementation.
img_idx: index of input video frame
sal_idx: index into corresponding global saliency map arrays
perturber: PerturbImage implementation
saliency_gen: GenerateClassifierConfidenceSaliency implementation
verbose: whether or not to print debug statements (default: 0)
"""
global actor_sal_maps
global critic_sal_maps
# Score reference frame
print_helper(f"[{img_idx}]Scoring frame", verbose)
ref_img = history["ins"][img_idx]
ref_img_proc = prepro(ref_img)
hx = torch.tensor(history["hx"][img_idx - 1]).view(1, -1)
cx = torch.tensor(history["cx"][img_idx - 1]).view(1, -1)
ref_img_tensor = torch.tensor(ref_img_proc.reshape(1, 1, 80, 80))
model_inp = (ref_img_tensor, (hx, cx))
ref_value, ref_logit, _ = model(model_inp)
ref_value = ref_value.detach().numpy()[0]
ref_logit = ref_logit.detach().numpy()[0]
# Get image perturbations
print_helper(f"[{img_idx}]Perturbing image", verbose)
pert_masks = perturber(ref_img_proc)
blurred_img = gaussian_filter(ref_img_proc, sigma=3)
pert_imgs = occlude_image_batch(ref_img_proc, pert_masks, fill=blurred_img)
pert_values = []
pert_logits = []
# Score perturbed frames
print_helper(f"[{img_idx}]Scoring perturbations", verbose)
for pert_img in pert_imgs:
pert_img_tensor = torch.tensor(pert_img.reshape(1, 1, 80, 80))
model_inp = (pert_img_tensor, (hx, cx))
pert_value, pert_logit, _ = model(model_inp)
pert_values.append(pert_value.detach().numpy()[0])
pert_logits.append(pert_logit.detach().numpy()[0])
# Generate actor saliency maps
print_helper(f"[{img_idx}]Generating actor saliency maps", verbose)
actor_sal_maps[sal_idx] = saliency_gen(ref_logit, pert_logits, pert_masks)
# Generate critic saliency maps
print_helper(f"[{img_idx}]Generating critic saliency maps", verbose)
critic_sal_maps[sal_idx] = saliency_gen(ref_value, pert_values, pert_masks)
def visualize_saliency(
frame: np.ndarray,
actor_sal_map: np.ndarray,
critic_sal_map: np.ndarray,
) -> np.ndarray:
"""Creates visualization of saliency by alpha-blending the provided frame and
saliency maps. The actor and critic saliency maps are scaled to [0,255] to
match the range of the frame and then blended as the blue and red channels
respectively.
"""
# Scale saliency maps to [0, 255] in respective color channel
sal_colors = np.zeros((210, 160, 3), dtype=np.uint8)
sal_colors[35:195, :, 2] = (255.0 * cv2.resize(src=actor_sal_map, dsize=(160, 160))).astype("uint8")
sal_colors[35:195, :, 0] = (255.0 * cv2.resize(src=critic_sal_map, dsize=(160, 160))).astype("uint8")
return cv2.addWeighted(frame, 0.4, sal_colors, 0.6, 0)
def app(
start_frame: int,
end_frame: int,
perturber: PerturbImage,
saliency_gen: GenerateClassifierConfidenceSaliency,
) -> None:
"""App for running breakout and peforming saliency generation."""
global actor_sal_maps
global critic_sal_maps
# Initialize map arrays to correct size
actor_sal_maps = [None] * (end_frame - start_frame + 1)
critic_sal_maps = [None] * (end_frame - start_frame + 1)
# Use threaded computation
def call_wrapper(idx: int) -> None:
"""Wrapper for gen_sal_maps."""
return gen_sal_maps(idx, idx - start_frame, perturber, saliency_gen)
tpe = concurrent.futures.ThreadPoolExecutor(max_workers=multiprocessing.cpu_count())
list(tpe.map(call_wrapper, range(start_frame, end_frame + 1)))
tpe.shutdown(wait=True)
# Write out videos
print("Creating video")
fps = 30
vid_writer = cv2.VideoWriter("data/breakout_saliency.mp4", cv2.VideoWriter_fourcc(*"vp09"), fps, (w, h))
for img_idx in range(start_frame, end_frame + 1):
sal_idx = img_idx - start_frame
frame = visualize_saliency(history["ins"][img_idx], actor_sal_maps[sal_idx], critic_sal_maps[sal_idx])
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR) # Convert to BGR to meet cv2 convention
vid_writer.write(frame)
vid_writer.release()
print("Done.")
Perturbation and Saliency Implementations
For this example we will use the SlidingRadial perturbation implementation with blurring using sigma values of (5,5) and stride of (5,5). Our filled image here will be a blurred version of the original image. We try to use the same parameters as in the original implementation.
The SquaredDifferenceScoring heatmap generation implementation is used here, following the authors’ approach in the paper. This will give an absolute sense of saliency for both the actor and critic models without distinguishing positive vs. negative.
from xaitk_saliency.impls.gen_classifier_conf_sal.squared_difference_scoring import SquaredDifferenceScoring
from xaitk_saliency.impls.perturb_image.sliding_radial import SlidingRadial
window_perturber = SlidingRadial(radius=(1, 1), stride=(5, 5), sigma=(5, 5))
sal_gen = SquaredDifferenceScoring()
Calling the Application
An arbitrary set of frames is chosen for saliency generation using our application and the resulting video is displayed below.
From the video it is apparent that the area above the paddle and around the ball seem to be very important to both the value and policy functions. We can also see that the value function is heavily affected by holes in the blocks. This suggests that the agent has learned to create these holes so that it can get the ball behind the blocks to earn a high reward quickly.
app(start_frame=638, end_frame=1238, perturber=window_perturber, saliency_gen=sal_gen)
Creating video
Done.
Here we show saliency (actor in blue, critic in red) overlaid on a single frame from the game.
f = plt.figure(figsize=[8, 12])
frame_ix = 1070
img = history["ins"][frame_ix]
viz = visualize_saliency(img, actor_sal_maps[frame_ix - 1020], critic_sal_maps[frame_ix - 1020])
plt.imshow(viz)
for a in f.axes:
a.get_xaxis().set_visible(False)
a.get_yaxis().set_visible(False)
plt.show()

Finally, we show a recorded video from the game with overlaid saliency (actor in blue, critic in red). This video is saved as breakout_saliency.mp4 in the current directory.
Note that this file will not exist, and the video will not be visible, until the notebook is run.
%%HTML
<div align="center">
<video width="50%" controls>
<source src="data/breakout_saliency.mp4" type="video/mp4">
</video>
</div>