Saliency Generation with MNIST Dataset
Introduction
The first example showcases the use of the xaitk-saliency API to generate visual saliency maps using models from the scikit-learn library trained on the MNIST dataset. The MNIST dataset contains grayscale images of handwritten digits (0-9), which are normalized and centered in the frame. It was developed to evaluate the performance of models classifying individual handwritten digits.
This example from scikit-learn’s website uses their LogisticRegression class to achieve fairly high accuracy on the MNIST dataset with very short training time.
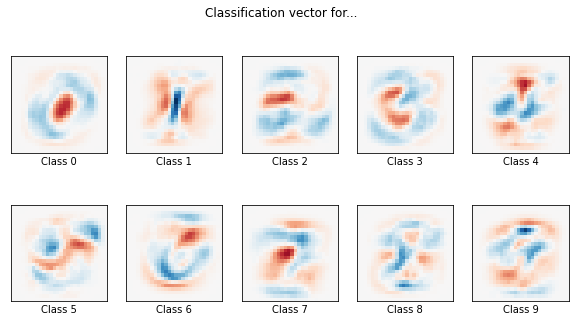
As is shown by this example, it is easy to visualize the decision boundaries of each class by simply plotting their respective model’s coefficients in the same dimensions as the input image.
We use the xaitk-saliency high-level API to mimic this visualization by creating saliency maps for several images from the dataset and averaging them to create a global decision-boundary representation for each class. This approach achieves comparable results to those shown in scikit-learn’s example while requiring zero knowledge of the intrinsic properties of the model used.
We do the same while using the MLPClassifier class also from the scikit-learn library.
Our model is taken from another example on their website.
The example shows a visualization of the MLP’s weights as images to gain insight on the learning behavior of the model.
These images, however, only show generic patterns that the model has learned and therefore the behavior of each class is still obscure.
Using our approach provides per-class saliency representations and also gives some insight on the different learning behaviors portrayed by both these models.
Table of Contents
To run this notebook in Colab, use the link below:
![]()
MNIST Dataset Example
Set Up Environment
Note for Colab users: after setting up the environment, you may need to “Restart Runtime” in order to resolve package version conflicts (see the README for more info).
import sys # noqa
!{sys.executable} -m pip install -qU pip
!{sys.executable} -m pip install -q xaitk-saliency
# for some reason scikit-learn is needing pandas in this notebook
!{sys.executable} -m pip install -q pandas
Downloading the Dataset
The MNIST dataset consists of 70,000 28x28 grayscale images of handwritten numbers. Each image is stored as a column vector, resulting in a (70000,784) shape for the entire dataset.
import os
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import fetch_openml
cwd = os.getcwd()
data_dir = cwd + "/data/scikit-learn-example"
# Load data from https://www.openml.org/d/554
X, y = fetch_openml("mnist_784", version=1, return_X_y=True, as_frame=False, data_home=data_dir)
X = X / X.max()
# Find examples of each class
ref_inds = [np.nonzero(np.int64(y) == i)[0][0] for i in range(10)]
ref_imgs = X[ref_inds]
# Plot examples
plt.figure(figsize=(15, 5))
for i in range(10):
plt.subplot(1, 10, i + 1)
plt.imshow(ref_imgs[i].reshape(28, 28), "gray")
plt.axis("off")
The “Application”
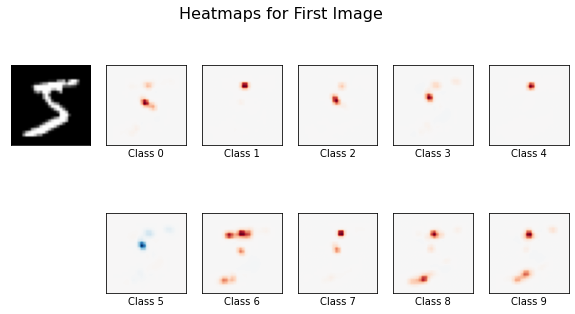
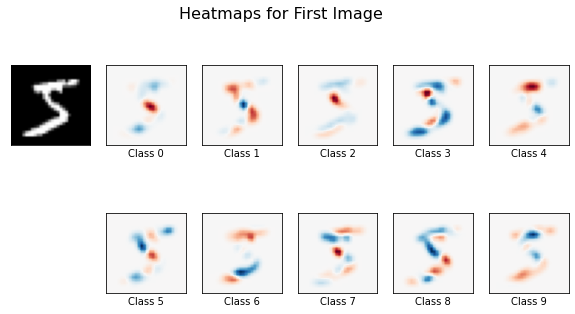
Our “application” will accept a set of images, a black-box image classifier, and a saliency generator and will generate saliency maps for each image provided. The saliency maps from the first image in the set will then be plotted to give an idea of the model’s behavior on a single sample.
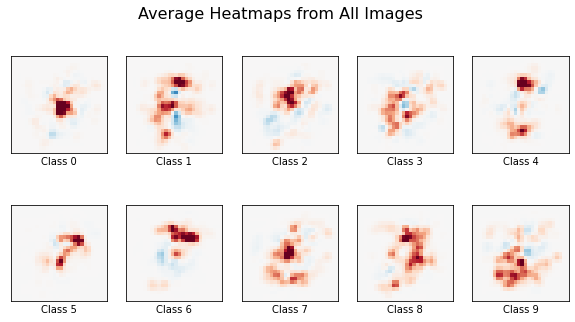
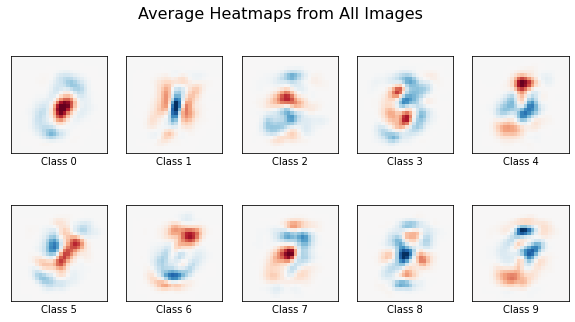
Additionally, because all digits in the MNIST dataset are centered in the frame, we can average all the heatmaps generated for each respective class to produce a decision boundary visualization. The application will do this and plot the resulting averaged heatmaps for each digit class. This should compare to what is shown in the first example discussed in the introduction.
from collections.abc import Iterable, Sequence
from typing import Any
from smqtk_classifier import ClassifyImage
from typing_extensions import override
from xaitk_saliency import GenerateImageClassifierBlackboxSaliency
def app(
images: np.ndarray,
image_classifier: ClassifyImage,
saliency_generator: GenerateImageClassifierBlackboxSaliency,
) -> None:
"""Helper to generate and visualize saliency maps"""
# Generate saliency maps
sal_maps_set = []
for img in images:
ref_image = img.reshape(28, 28)
sal_maps = saliency_generator(ref_image, image_classifier)
sal_maps_set.append(sal_maps)
num_classes = sal_maps_set[0].shape[0]
# Plot first image in set with saliency maps
plt.figure(figsize=(10, 5))
plt.suptitle("Heatmaps for First Image", fontsize=16)
num_cols = np.ceil(num_classes / 2).astype(int) + 1
plt.subplot(2, num_cols, 1)
plt.imshow(images[0].reshape(28, 28), cmap="gray")
plt.xticks(())
plt.yticks(())
for c in range(num_cols - 1):
plt.subplot(2, num_cols, c + 2)
plt.imshow(sal_maps_set[0][c], cmap=plt.cm.RdBu, vmin=-1, vmax=1)
plt.xticks(())
plt.yticks(())
plt.xlabel(f"Class {c}")
for c in range(num_classes - num_cols + 1, num_classes):
plt.subplot(2, num_cols, c + 3)
plt.imshow(sal_maps_set[0][c], cmap=plt.cm.RdBu, vmin=-1, vmax=1)
plt.xticks(())
plt.yticks(())
plt.xlabel(f"Class {c}")
# Average heatmaps for each respective class
global_maps = np.sum(sal_maps_set, axis=0) / len(images)
# Plot average maps
plt.figure(figsize=(10, 5))
plt.suptitle("Average Heatmaps from All Images", fontsize=16)
for c in range(num_classes):
vcap = np.absolute(global_maps[i]).max()
plt.subplot(2, num_cols - 1, c + 1)
plt.imshow(global_maps[c], cmap=plt.cm.RdBu, vmin=-vcap, vmax=vcap)
plt.xticks(())
plt.yticks(())
plt.xlabel(f"Class {c}")
Logistic Regression Example
Fitting the Model
We take the same LogisticRegression object used in the scikit-learn example and fit it to a subset of the dataset.
Here, an L2 penalty and a larger training set is used to yield slightly better results than those shown in the example.
The same visualization of the coefficients is shown with these new parameters.
import time
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
t0 = time.time()
# Split data into test and train sets
train_samples = 20000
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=train_samples, test_size=10000, random_state=0)
# Define model, lower C value gives higher regulation
clf = LogisticRegression(C=50.0 / train_samples, penalty="l2", solver="saga", tol=0.1, random_state=0)
# Fit model
clf.fit(X_train, y_train)
# Score model
score = clf.score(X_test, y_test)
print(f"Test score with L2 penalty: {score:.4f}")
# Visualize coefficients
coef = clf.coef_.copy()
max_val = np.abs(coef).max()
plt.figure(figsize=(10, 5))
for i in range(10):
p = plt.subplot(2, 5, i + 1)
p.imshow(coef[i].reshape(28, 28), cmap=plt.cm.RdBu, vmin=-max_val, vmax=max_val)
p.set_xticks(())
p.set_yticks(())
p.set_xlabel(f"Class {i}")
plt.suptitle("Classification vector for...")
run_time = time.time() - t0
print(f"Example run in {run_time:.3f} s")
plt.show()
Test score with L2 penalty: 0.8865
Example run in 2.445 s
Black-Box Classifier
Here we wrap our LogisticRegression object in SMQTK-Classifier’s ClassifyImage class to comply with the API’s interface.
class MNISTClassifierLog(ClassifyImage):
"""ClassifyImage wrapper for LogisticRegression"""
@override
def get_labels(self) -> Sequence[int]:
"""Return class labels"""
return list(range(10))
@override
def classify_images(self, image_iter: Iterable[np.ndarray]) -> Sequence[dict[str, Any]]:
"""Generate predictions"""
# Yes, "images" in this example case are really 1-dim (28*28=784).
# MLP input needs a (n_samples, n_features) matrix input.
images = np.asarray(list(image_iter)) # may fail because input is not consistent in shape
images = images.reshape(-1, 28 * 28) # may fail because input was not the correct shape
return (dict(zip(range(10), p, strict=False)) for p in clf.decision_function(images))
@override
def get_config(self) -> dict[str, Any]:
"""Required for implementation"""
return {}
image_classifier_log = MNISTClassifierLog()
Heatmap Generation
We create an instance of SlidingWindowStack, an implementation of the GenerateImageClassifierBalckboxSaliency interface, to carry out our image perturbation and heatmap generation.
from xaitk_saliency.impls.gen_image_classifier_blackbox_sal.slidingwindow import SlidingWindowStack
gen_sliding_window = SlidingWindowStack(window_size=(2, 2), stride=(1, 1), threads=4)
Calling the Application
Finally, we call the application using the first 20 images in the MNIST dataset. Here the blue is showing positive saliency while the red is showing negative saliency.
Even with a small set of images, the general shape of the digits is visible. Using a larger set of images should improve the visualized decision boundaries, but scales the computation time linearly.
These results are largely expected when linear models like logistic regression are used. Each pixel from the image corresponds to a single coefficient in each of the respective classes’ regressions. Occluding a pixel in the image should affect the output of the model, and therefore the resulting saliency maps, proportional to the value of the corresponding coefficients. We therefore expect the saliency maps to largely match the pattern of the learned coefficients.
app(X[0:20], image_classifier_log, gen_sliding_window)
MLP Example
Fitting the Model
Following the second example from scikit-learn, we training an MLPClassifier on the MNIST dataset using the same hyperparameters.
To shorten training time, the MLP has only one hidden layer with 50 nodes, and is only trained for 10 iterations, meaning the model does not converge.
import warnings
from sklearn.exceptions import ConvergenceWarning
from sklearn.neural_network import MLPClassifier
# use the traditional train/test split
X_train, X_test = X[:60000], X[60000:]
y_train, y_test = y[:60000], y[60000:]
mlp = MLPClassifier(
hidden_layer_sizes=(50,),
max_iter=10,
alpha=1e-4,
solver="sgd",
verbose=10,
random_state=1,
learning_rate_init=0.1,
)
# this example won't converge because of CI's time constraints, so we catch the
# warning and ignore it here
with warnings.catch_warnings():
warnings.filterwarnings("ignore", category=ConvergenceWarning, module="sklearn")
mlp.fit(X_train, y_train)
print(f"Training set score: {mlp.score(X_train, y_train):f}")
print(f"Test set score: {mlp.score(X_test, y_test):f}")
Iteration 1, loss = 0.32009978
Iteration 2, loss = 0.15347534
Iteration 3, loss = 0.11544755
Iteration 4, loss = 0.09279764
Iteration 5, loss = 0.07889367
Iteration 6, loss = 0.07170497
Iteration 7, loss = 0.06282111
Iteration 8, loss = 0.05530788
Iteration 9, loss = 0.04960484
Iteration 10, loss = 0.04645355
Training set score: 0.986800
Test set score: 0.970000
Black-Box Classifier
We wrap our MLPClassifier object in SMQTK-Classifier’s ClassifyImage class to comply with the API’s interface.
class MNISTClassifierMLP(ClassifyImage):
"""ClassifyImage wrapper for MLPClassifier"""
@override
def get_labels(self) -> Sequence[int]:
"""Return class labels"""
return list(range(10))
@override
def classify_images(self, image_iter: Iterable[np.ndarray]) -> Sequence[dict[str, Any]]:
"""Generate predictions"""
# Yes, "images" in this example case are really 1-dim (28*28=784).
# MLP input needs a (n_samples, n_features) matrix input.
images = np.asarray(list(image_iter)) # may fail because input is not consistent in shape
images = images.reshape(-1, 28 * 28) # may fail because input was not the correct shape
return (dict(zip(range(10), p, strict=False)) for p in mlp.predict_proba(images))
@override
def get_config(self) -> dict[str, Any]:
"""Required for implementation"""
return {}
image_classifier_mlp = MNISTClassifierMLP()
Calling the Application
We call our application again using the same image set and saliency generator, but this time using our MLP classifier.
The results show mostly negative saliency, suggesting that the MLP model has learned where the pixels are absent for each class more than where they are present.
app(X[0:20], image_classifier_mlp, gen_sliding_window)