Introduction
The xaitk-saliency package implements a class of XAI algorithms known as saliency algorithms. A basic machine learning application pipeline is shown in Figure 1:
Figure 1: A basic AI pipeline.
In this scenario, an AI algorithm operates on an input (text, image, etc.) to produce some sort of output (classification, detection, etc.). Saliency algorithms build on this to produce visual explanations in the form of saliency maps as shown in Figure 2:
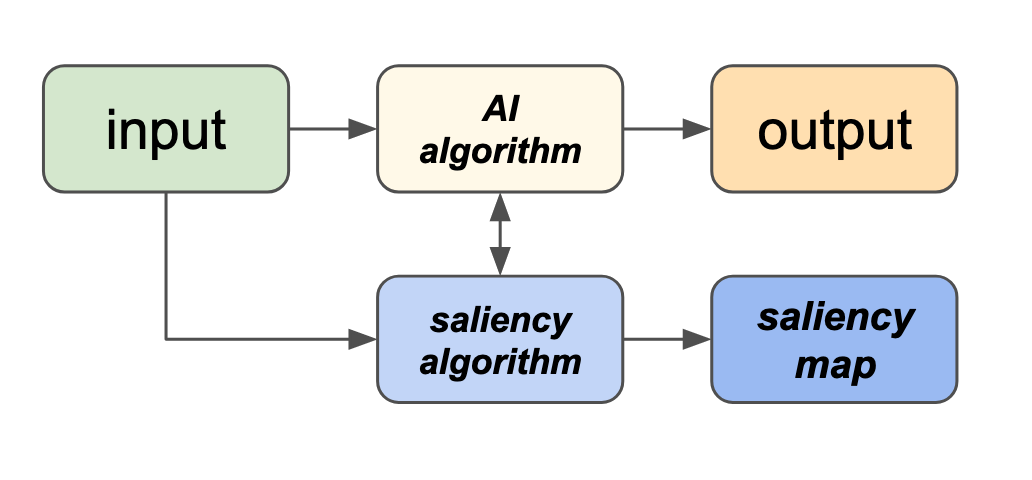
Figure 2: The AI pipeline augmented with a saliency algorithm.
At a high level, saliency maps are typically colored heatmaps applied to the input, highlighting regions that are somehow significant to the AI. Figure 3 shows sample saliency maps for text and images.

Figure 3: Sample saliency maps for text (left, from Tuckey et al.) and images (right, from Dong et al.).
Note
The xaitk-saliency toolkit currently focuses on providing saliency maps for images.
Image Saliency Maps: An Intuitive Introduction
Figure 4 shows a deep learning pipeline for recognizing objects in images; pixels in the image (in green) are processed by the Convolutional Neural Network (CNN, in yellow) to produce the output (in orange). Here, the system has been trained to recognize 1000 object categories. Its output is a list of 1000 numbers, one for each object type; each number is between 0 and 1, representing the system’s estimate of whether or not that particular object is in the image.
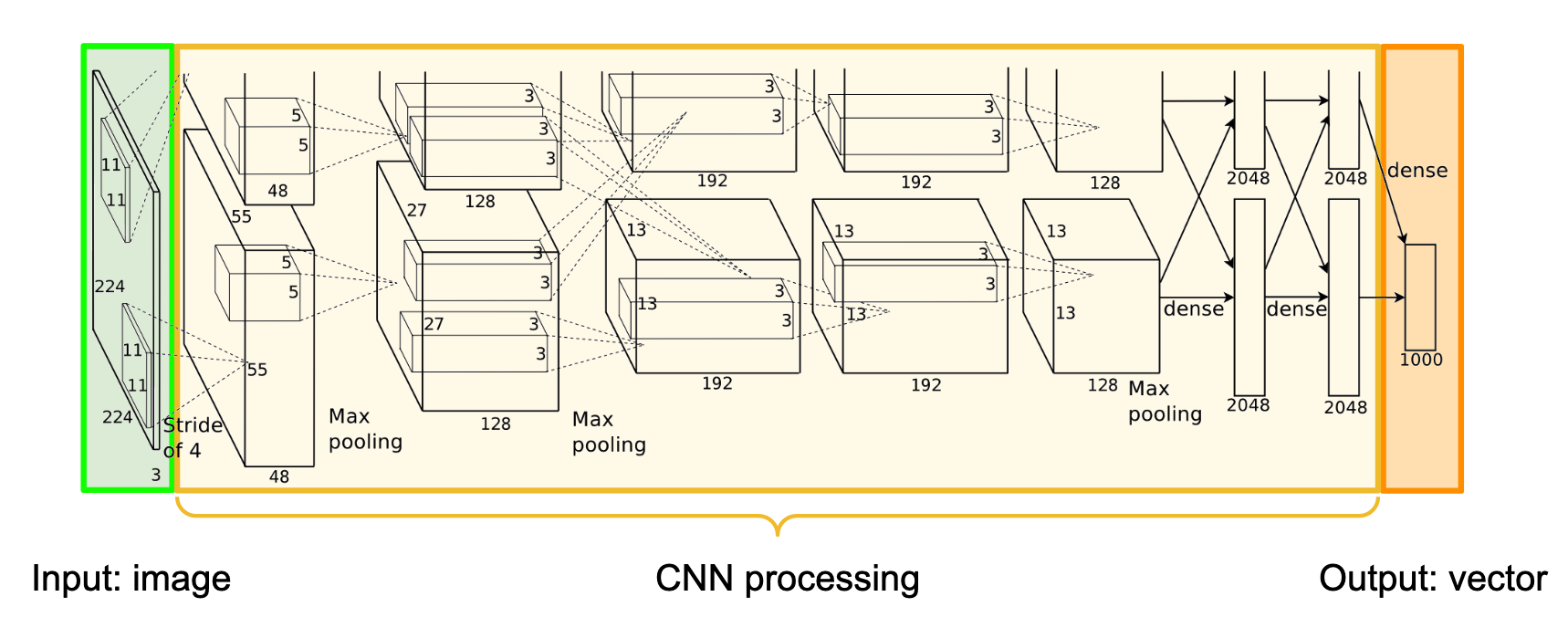
Figure 4: Typical object recognition CNN architecture; the image (green, left) is processed left to right through the CNN (yellow) to produce an output vector (orange, right). Diagram from Krizhevsky et al.
This operation is “all or nothing” at both ends: the entire image must be processed, and the entire vector must be output. There is no mechanism by which a subset of the output can be traced back to a subset of the input. Yet it seems reasonable to ask questions such as:
The input image is a camel; why did the system give a higher likelihood to “horse” than “camel”?
The input image is a kitchen, but the system gave a high likelihood to “beach ball”. What parts of the image were responsible for this?
The input image contains two dogs, and the system gave a high likelihood for “dog”. How would this change if one of the dogs wasn’t in the image?
The input image contains a dog and a cat, and the system gave a high likelihood for “cat” but not “dog”. How will the system respond if the cat is removed?
At some level, these questions require a degree of introspection; the system must produce not only the output, but also some information about how the output was produced.
To avoid confusion, we need some definitions:
The AI algorithm, or AI, is the algorithm whose output we are trying to explain. An AI operates according to its AI model; contemporary AIs are built around CNNs such as in Figure 4, examples of other models include decision trees and support vector machines.
Explainable AI algorithms, or XAI, is what we attach to the AI system to generate explanations (as in Figure 2). The XAI may itself use CNNs, but these details are typically hidden from the XAI user.
To answer questions such as the ones raised above, the XAI must have some way of interacting with the AI. There are two popular approaches to this:
The white-box approach: the AI system is altered to open or expose its model. The XAI examines the state of the AI model as the AI generates its output, and uses this information to create the explanation.
The black-box approach: the AI’s model is not exposed; instead, the XAI probes the AI by creating an additional set of input images which perturb or change the original input in some way. By comparing the original output to that for the related images, we can deduce certain aspects of the how the AI and its model behaves.
These are illustrated in Figure 5. Note how the AI algorithm is not available for inspection in the black-box model.
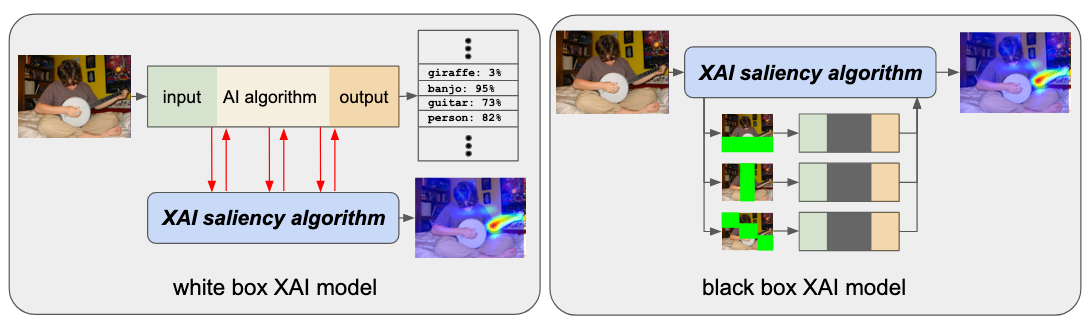
Figure 5: White-box vs. black-box approaches to XAI. The white-box approach has access to the AI model; the black-box approach does not and instead repeatedly probes the AI with variations on the input image.
Note
The white-box vs. black-box distinction refers to using the AI model after it has been created; nothing is implied about how the model is constructed.
Let’s take a look at the pros and cons of these two approaches.
White-Box Methods
The white-box approach to XAI (Figure 5, left) exposes some (or all) of the internal state of the AI model; the explanation draws a connection between this exposed state and the AI’s output. Some AI methods are intrinsically introspective to the point where they are not so much “white-box” as transparent:
In linear regression, the output is a weighted sum of input features, making it easy to separate out effects just by looking at each of the learned-feature weights.
In a decision tree, the output is directly computed by making the comparisons through a set of nodes and branches that are part of the AI’s model.
An example of a white-box explanation method for CNNs is Grad-CAM (paper, code), which exposes some (but not all) of the CNN layers to the explanation generation algorithm.
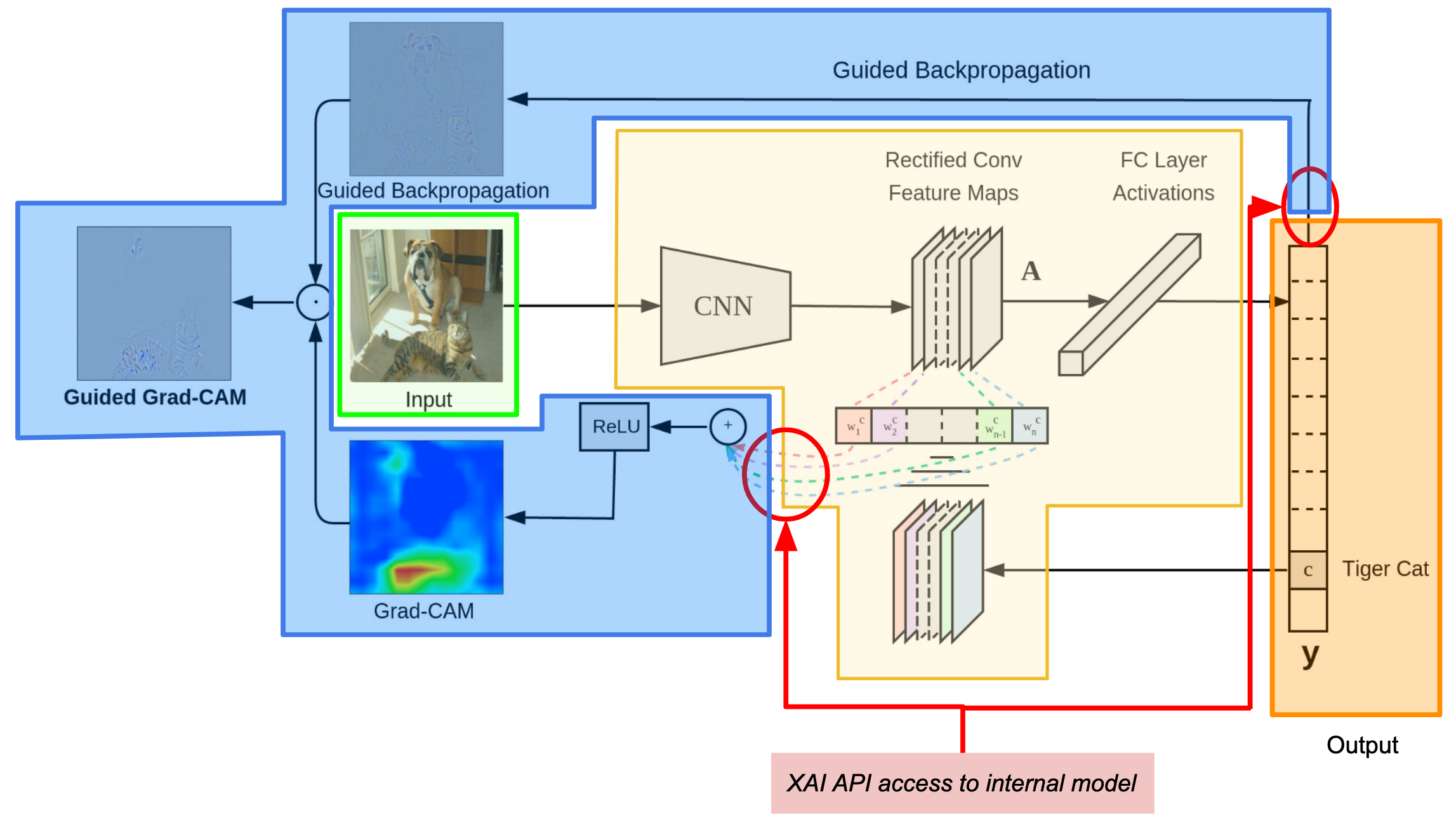
Figure 6: Grad-CAM architecture. Functional regions annotated to align with Figure 4: input in green, CNN architecture in yellow, output in orange. The explanation functionality is in blue; the APIs granting access to the model are circled in red. Figure from the Grad-CAM code repo.
In Grad-CAM, first the model computes its output per the typical processing flow: input (green), through the CNN (yellow), to the output (orange.) The explanation is created via an additional processing step that uses the output and feature maps from within the CNN (made available to the XAI through the red circles) to measure and visualize the activation of those regions associated with the output (orange).
Two aspects typical of white-box methods are demonstrated here:
The explanation could not have been created from the output alone. In order to operate, the explanation algorithm (blue) required access to both the output and the CNN internal state.
The XAI implementation is tightly coupled to the AI’s CNN model architecture exposed by the API. Although the method may be general, any particular implementation will expect the AI’s CNN architecture to conform to the specifics of the API.
In general, pros and cons of white-box approaches are:
Pros
A white-box XAI can choose to leverage its tight coupling to the AI model to maximize the information available, at the sacrifice of generalization to other AI models.
A white-box XAI accesses the actual AI model’s computation which generated the output. The explanation is derived directly from what the AI model computed about the input, in contrast to black-box XAIs which can only indirectly compare the output to output from slightly different inputs.
A white-box XAI is usually more computationally efficient, since it typically only requires a single forward / backward pass through the AI model. In Figure 5, the white-box approach on the left interacts with the AI during its single processing run to produce the output; in comparison, black-box methods (such as in Figure 5 on the right) typically run the AI network multiple times.
Cons
The flip side of tighter XAI integration to a specific AI model or class of models is loss of generality. An explanation technique that works for one model can be difficult to port to other AI models. Lack of generality can also make it harder to evaluate explanation algorithms across AI models.
It may be necessary to modify the AI model implementation to gain access to the internal state. Depending on the environment in which the AI was developed and delivered, this problem may be trivial or insurmountable.
Similarly, the white-box XAI may require updating as the AI model evolves. Tight coupling introduces a dependency which must be managed, possibly increasing development costs.
Black-Box Methods
One way to frame the AI pipeline in Figure 1 is that we’re asking the AI a question (the input), and it gives us an answer (the output). In this setting, a white-box XAI uses its special access to the AI model to observe details of how the AI answers the question. In contrast, a black-box XAI (Figure 5, right) does not see any details of how the AI answers a single question; rather, it asks the AI a series of different questions related to the original input and bases its explanation on how these answers differ from the original answer.
This technique relies on two assumptions:
We have some way to generate these “related questions” based on the original input whose output we’re trying to explain.
The AI algorithm’s responses to these additional questions will somehow “add up” to an explanation for the original output.
The xaitk-saliency package deals with image-based AI; black-box XAI for images typically generate the “related questions” by image perturbation techniques. These repeatedly change or partially obscure the input image to create new images to run through the AI, which in turn generates the “related answers” the XAI uses to form its explanation.
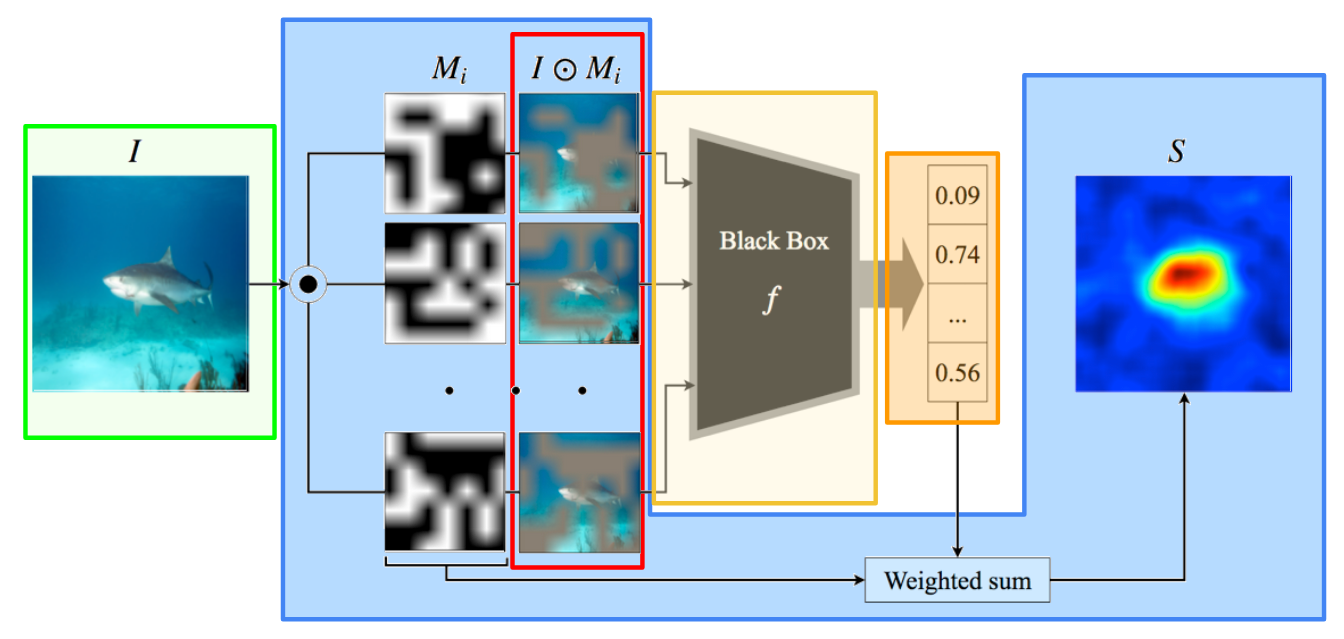
Figure 7: RISE architecture. Functional regions annotated to align with Figure 4: input in green, AI in yellow, output in orange. Note that the operation of the AI is not exposed to the XAI. The XAI (in blue) creates the set of related inputs (red box) by randomly obscuring areas of the input. Figure from Petsiuk, Das, and Saenko.
Figure 7 shows the architecture for one black-box XAI algorithm, RISE (Randomized Input Sampling for Explanation). When applied to an image classification AI algorithm, RISE generates an “importance map” indicating which regions of the input are most associated with high confidence for a particular label. This is done by creating copies of the input with areas randomly obscured (shown in the red box in Figure 7). Each of these is fed through the AI; by comparing how the outputs change, RISE develops a correlation between image areas and label confidences.
Two aspects typical of black-box methods are demonstrated here:
The explanation does not require access to the inner workings of the AI. RISE is black box because it only uses the AI’s standard input and output pathways.
The AI must be run many times on different inputs to generate the explanation. In the experiments described in their paper, the RISE team used up to 8000 masked versions of a single input image to generate an explanation.
In general, pros and cons of black-box approaches are:
Pros
A black-box XAI does not depend on the AI method, only the inputs and outputs. (It is said to be model-agnostic.) In Figure 7, the AI (in yellow) can be anything: a CNN, a decision tree, or random number generator. This independence is the primary appeal of black-box methods, and has several implications:
A single black-box XAI can, in theory, operate across any number of AI implementations. As long as the AI provides input and output as in Figure 1, it can be used with a black-box XAI.
Black-box XAIs are loosely coupled to the AIs they explain. As long as the basic I/O pathways are unchanged, the AI has more freedom to evolve at a different pace from the XAI.
The black-box approach enables XAI when the AI must not be exposed, due to security concerns, contractual agreements, etc.
Cons
Black-box XAI approaches require extra work to generate and process the related inputs. As a result, they are generally slower and more resource intensive than white-box approaches.
A black-box XAI can only indirectly observe how the AI processes the original input. A white-box XAI’s explanation directly uses how the AI responds to the input, but for any one input, a black-box XAI can never know anything beyond the output. Processing an array of related inputs provides indirect / differential insight into the AI’s behavior, but a black-box XAI cannot relate this behavior to anything inside the AI.
Saliency Algorithms
The xaitk-saliency package currently provides several black-box XAI algorithms. These algorithms follow a general pattern that consists of two sequential steps: image perturbation followed by heatmap generation. Image perturbation involves generating perturbed versions of the input image by applying a set of perturbation masks. Heatmap generation involves generating saliency heatmaps based on how the black-box model outputs change as a result of image perturbation. This technical design choice allows for modularization of the image perturbation and heatmap generation components of the algorithm. By formulating the algorithms in this manner, the exact operation of the black-box model is not needed by an algorithm, which is concerned only with the inputs and outputs. Additionally, the algorithm can be flexibly determined by the user; that is, the user is free to choose and configure the algorithm as needed for the problem domain.
The saliency algorithms can also be organized according to their respective tasks:
Task |
Saliency Algorithm(s) |
|---|---|
Image classification |
Occlusion-based Saliency [1]; Randomized Input Sampling for Explanation (RISE) [2] |
Image similarity |
|
Object detection |
|
Reinforcement learning |
Zeiler MD, Fergus R. Visualizing and understanding convolutional networks (2013). arXiv preprint arXiv:1311.2901. 2013.
Petsiuk V, Das A, Saenko K. Rise: Randomized input sampling for explanation of black-box models. arXiv preprint arXiv:1806.07421. 2018 Jun 19.
Dong B, Collins R, Hoogs A. Explainability for Content-Based Image Retrieval. In CVPR Workshops 2019 Jun (pp. 95-98).
Petsiuk V, Jain R, Manjunatha V, Morariu VI, Mehra A, Ordonez V, Saenko K. Black-box explanation of object detectors via saliency maps. arXiv preprint arXiv:2006.03204. 2020 Jun 5.
Greydanus S, Koul A, Dodge J, Fern A. Visualizing and understanding atari agents. In International conference on machine learning 2018 Jul 3 (pp. 1792-1801). PMLR.